ToolScape
Improving the learning experience of how-to videos
ToolScape: Step-Aware Video Player
ToolScape is an interactive video player that displays step descriptions and intermediate result thumbnails in the video timeline. Learners in our study performed better and gained more self-efficacy using ToolScape versus a traditional video player.
Annotated Screenshot

Interactive Demo
Crowdsourcing workflow
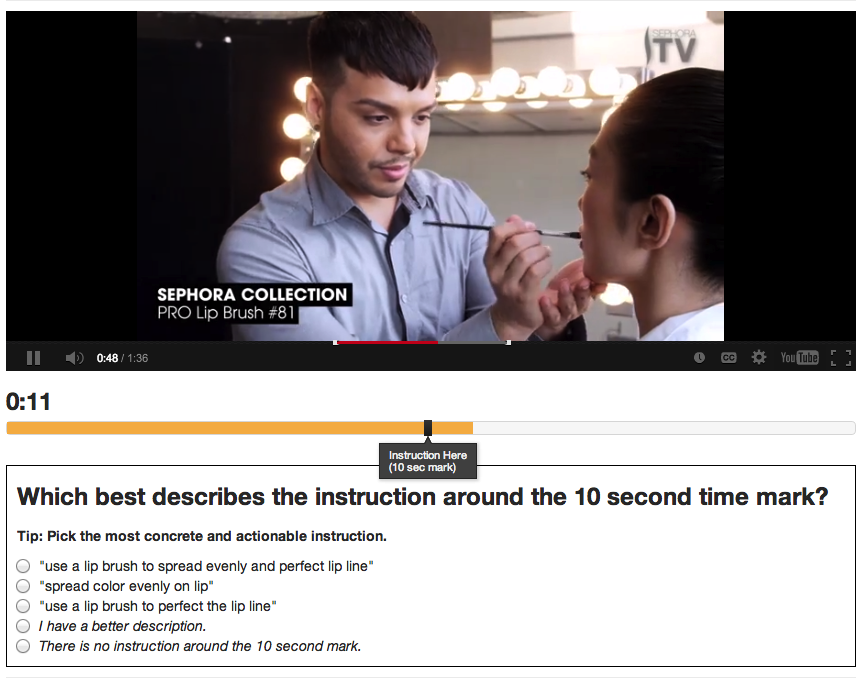
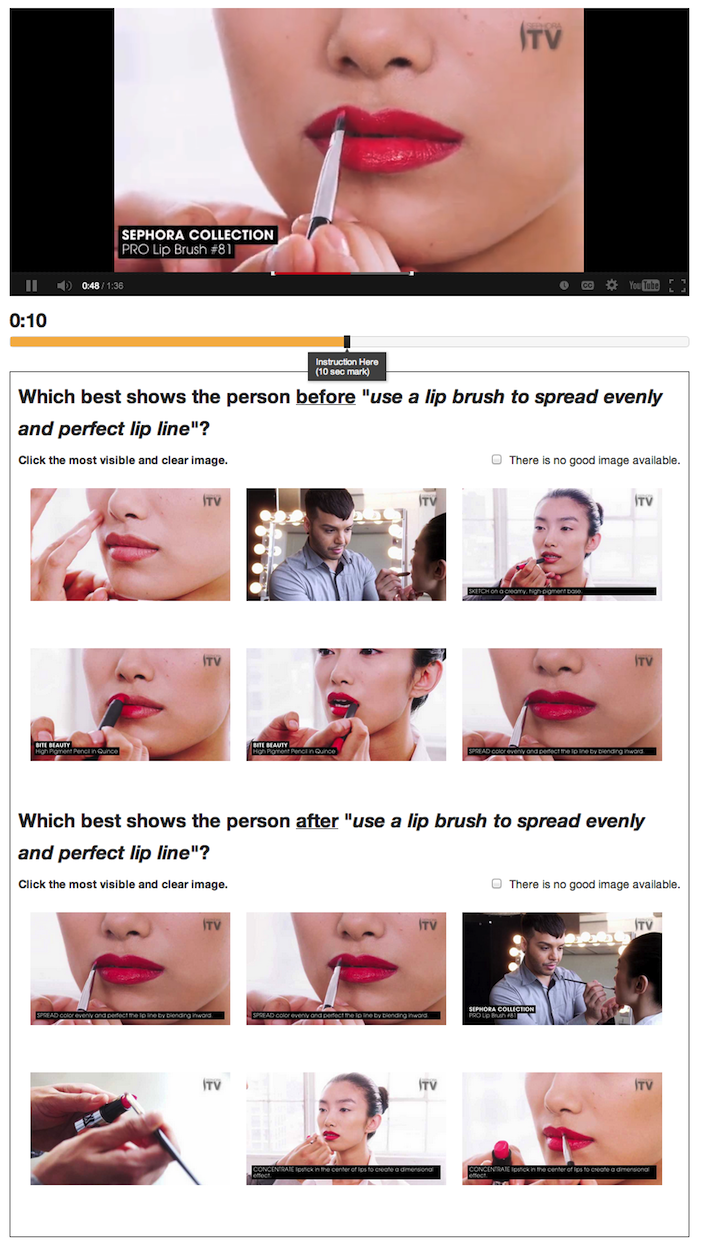
To add the needed step annotations to existing how-to videos at scale, we introduce a novel crowdsourcing workflow. It extracts step-by-step structure from an existing video, including step times, descriptions, and before and after images. We introduce the Find-Verify-Expand design pattern for temporal and visual annotation, which applies clustering, text processing, and visual analysis algorithms to merge crowd output. The workflow does not rely on domain-specific customization, works on top of existing videos, and recruits untrained crowd workers. We evaluated the workflow with Mechanical Turk, using 75 cooking, makeup, and Photoshop videos on YouTube. Results show that our workflow can extract steps with a quality comparable to that of trained annotators across all three domains with 77% precision and 81% recall.
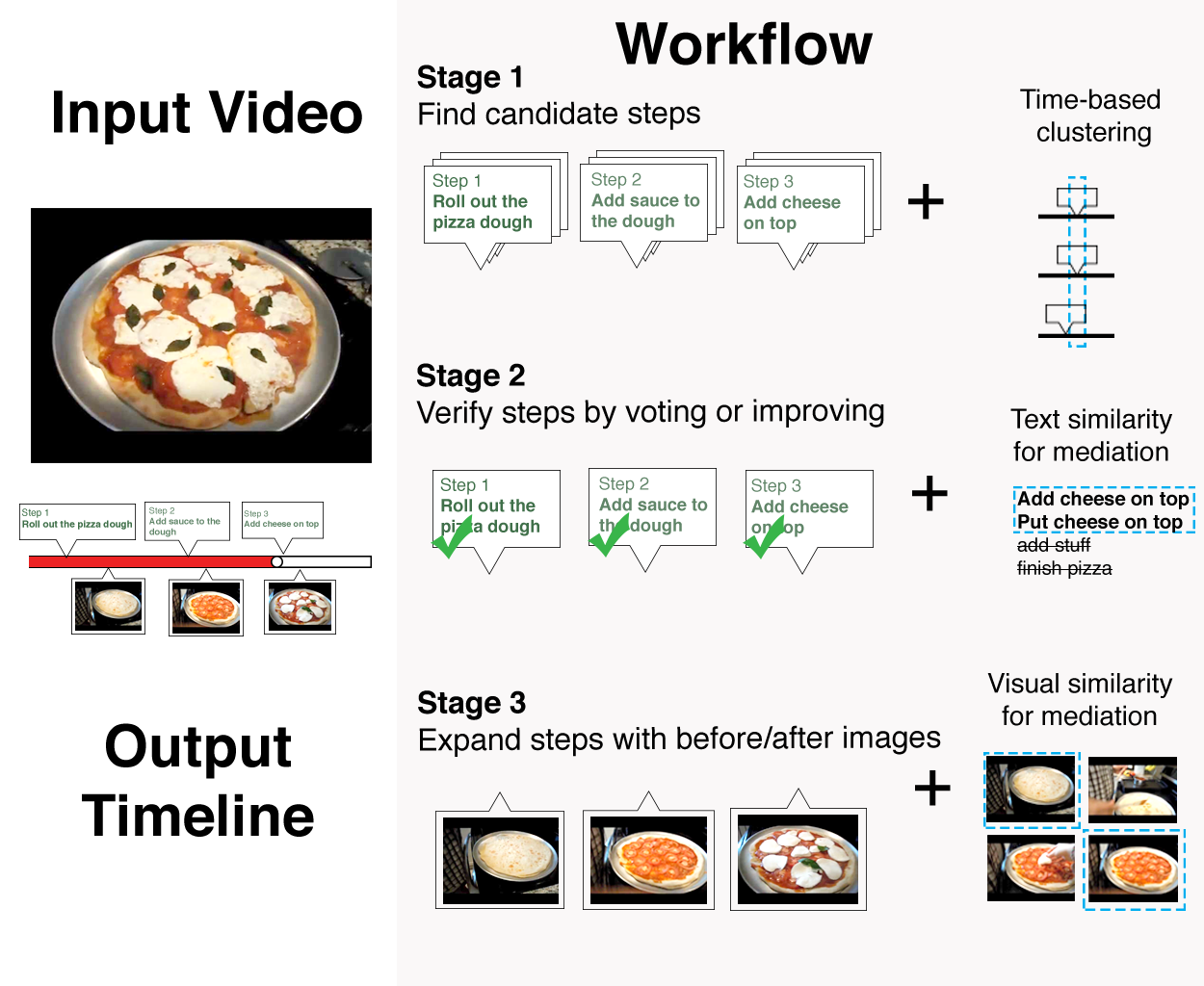
Stage 1. Find candidate steps
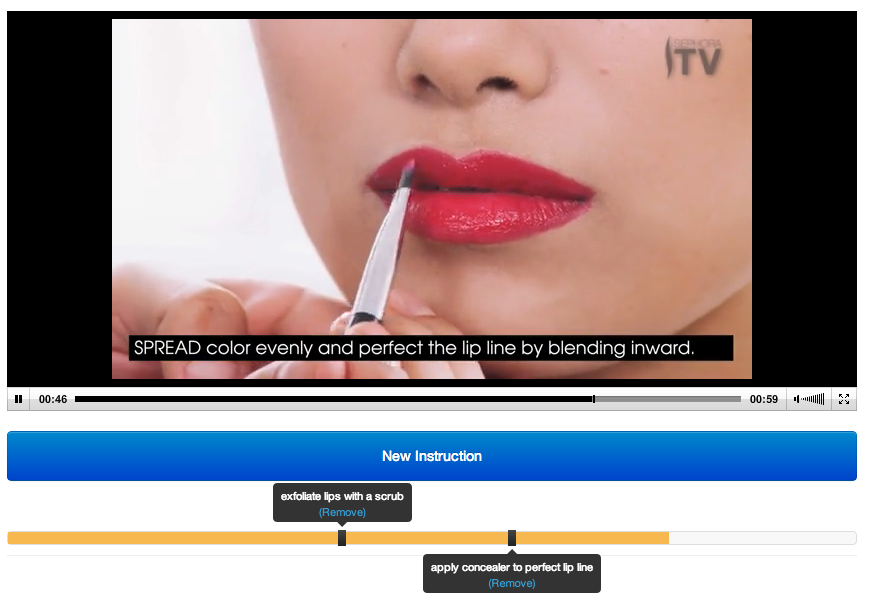
Stage 2. Verify steps by voting or improving
Stage 3. Expand steps with before/after images
People
- Juho Kim (MIT CSAIL)
- Phu Nguyen (MIT CSAIL)
- Sarah Weir (MIT CSAIL)
- Philip J. Guo (MIT CSAIL, University of Rochester)
- Krzysztof Z. Gajos (Harvard EECS)
- Robert C. Miller (MIT CSAIL)